
2024
Kandukuri, R. K., Strecke, M., Stueckler, J.
Physics-Based Rigid Body Object Tracking and Friction Filtering From RGB-D Videos
In Proceedings of the International Conference on 3D Vision (3DV), 2024 (inproceedings)
Achterhold, J., Guttikonda, S., Kreber, J. U., Li, H., Stueckler, J.
Learning a Terrain- and Robot-Aware Dynamics Model for Autonomous Mobile Robot Navigation
CoRR abs/2409.11452, 2024, Preprint submitted to Robotics and Autonomous Systems Journal. https://arxiv.org/abs/2409.11452 (techreport) Submitted
Strecke, M., Stueckler, J.
Physically Plausible Object Pose Refinement in Cluttered Scenes
In Proceedings of the German Conference on Pattern Recognition (GCPR), 2024, to appear (inproceedings) To be published
Kirchdorfer, L., Elich, C., Kutsche, S., Stuckenschmidt, H., Schott, L., Köhler, J. M.
Analytical Uncertainty-Based Loss Weighting in Multi-Task Learning
In Proceedings of the German Conference on Pattern Recognition (GCPR), 2024, to appear (inproceedings) To be published
Krimmel, M., Achterhold, J., Stueckler, J.
Attention Normalization Impacts Cardinality Generalization in Slot Attention
In Transactions on Machine Learning Research (TMLR), 2024 (article)
Xue, Y., Li, H., Leutenegger, S., Stueckler, J.
Event-based Non-Rigid Reconstruction of Low-Rank Parametrized Deformations from Contours
International Journal of Computer Vision (IJCV), 2024 (article)
Baumeister, F., Mack, L., Stueckler, J.
Incremental Few-Shot Adaptation for Non-Prehensile Object Manipulation using Parallelizable Physics Simulators
CoRR abs/2409.13228, CoRR, 2024, Submitted to IEEE International Conference on Robotics and Automation (ICRA) 2025 (techreport) Submitted
Elich, C., Kirchdorfer, L., Köhler, J. M., Schott, L.
Examining Common Paradigms in Multi-Task Learning
In Proceedings of the German Conference on Pattern Recognition (GCPR), 2024, to appear (inproceedings) To be published
Li, H., Stueckler, J.
Online Calibration of a Single-Track Ground Vehicle Dynamics Model by Tight Fusion with Visual-Inertial Odometry
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2024 (inproceedings)
2023
Achterhold, J., Tobuschat, P., Ma, H., Büchler, D., Muehlebach, M., Stueckler, J.
Black-Box vs. Gray-Box: A Case Study on Learning Table Tennis Ball Trajectory Prediction with Spin and Impacts
In Proceedings of the 5th Annual Learning for Dynamics and Control Conference (L4DC), 211, pages: 878-890, Proceedings of Machine Learning Research, (Editors: Nikolai Matni, Manfred Morari and George J. Pappa), PMLR, June 2023 (inproceedings)
Strecke, M. F.
Object-Level Dynamic Scene Reconstruction With Physical Plausibility From RGB-D Images
Eberhard Karls Universität Tübingen, Tübingen, 2023 (phdthesis)

Dhédin, V., Li, H., Khorshidi, S., Mack, L., Ravi, A. K. C., Meduri, A., Shah, P., Grimminger, F., Righetti, L., Khadiv, M., Stueckler, J.
Visual-Inertial and Leg Odometry Fusion for Dynamic Locomotion
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2023 (inproceedings)
Elich, C., Armeni, I., Oswald, M. R., Pollefeys, M., Stueckler, J.
Learning-based Relational Object Matching Across Views
In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2023 (inproceedings)
Guttikonda, S., Achterhold, J., Li, H., Boedecker, J., Stueckler, J.
Context-Conditional Navigation with a Learning-Based Terrain- and Robot-Aware Dynamics Model
In Proceedings of the European Conference on Mobile Robots (ECMR), 2023 (inproceedings)
2022
Elich, C., Oswald, M. R., Pollefeys, M., Stueckler, J.
Weakly Supervised Learning of Multi-Object 3D Scene Decompositions Using Deep Shape Priors
Computer Vision and Image Understanding (CVIU), 220, July 2022 (article)
Li, H., Stueckler, J.
Visual-Inertial Odometry with Online Calibration of Velocity-Control Based Kinematic Motion Models
IEEE Robotics and Automation Letters, 7(3):6415-6422, July 2022, Accepted for oral presentation at IEEE ICRA 2023 (article)
Li, H., Stueckler, J.
Observability Analysis of Visual-Inertial Odometry with Online Calibration of Velocity-Control Based Kinematic Motion Models
abs/2204.06651, CoRR/arxiv, 2022 (techreport)
Xue, Y., Li, H., Leutenegger, S., Stueckler, J.
Event-based Non-Rigid Reconstruction from Contours
In Proceedings of the British Machine Vision Conference (BMVC), 2022 (inproceedings)
Achterhold, J., Krimmel, M., Stueckler, J.
Learning Temporally Extended Skills in Continuous Domains as Symbolic Actions for Planning
In Proceedings of The 6th Conference on Robot Learning , 205, pages: 225-236 , Proceedings of Machine Learning Research , 6th Annual Conference on Robot Learning (CoRL 2022) , 2022 (inproceedings)
2021
Strecke, M., Stückler, J.
DiffSDFSim: Differentiable Rigid-Body Dynamics With Implicit Shapes
In 2021 International Conference on 3D Vision (3DV 2021) , pages: 96-105 , International Conference on 3D Vision (3DV 2021) , December 2021 (inproceedings)
Strecke, M., Stückler, J.
Physically Plausible Tracking & Reconstruction of Dynamic Objects
KIT Science Week Scientific Conference & DGR-Days 2021, October 2021 (talk)
Achterhold, J., Stueckler, J.
Explore the Context: Optimal Data Collection for Context-Conditional Dynamics Models
In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics (AISTATS 2021) , 130, JMLR, Cambridge, MA, Titel The 24th International Conference on Artificial Intelligence and Statistics (AISTATS 2021) , April 2021, preprint CoRR abs/2102.11394 (inproceedings)
Li, H., Stueckler, J.
Tracking 6-DoF Object Motion from Events and Frames
In Proc. of IEEE Int. Conf. on Robotics and Automation (ICRA), 2021 (inproceedings)
Kandukuri, R., Achterhold, J., Moeller, M., Stueckler, J.
Physical Representation Learning and Parameter Identification from Video Using Differentiable Physics
International Journal of Computer Vision, 130, pages: 3-16, 2021 (article)
2020
Strecke, M., Stückler, J.
Where Does It End? - Reasoning About Hidden Surfaces by Object Intersection Constraints
In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), pages: 9589 - 9597, IEEE, Piscataway, NJ, IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR 2020), June 2020, preprint Corr abs/2004.04630 (inproceedings)
Wang, R., Yang, N., Stückler, J., Cremers, D.
DirectShape: Photometric Alignment of Shape Priors for Visual Vehicle Pose and Shape Estimation
In Proceedings of the IEEE international Conference on Robotics and Automation (ICRA), pages: 11067 - 11073, IEEE, Piscataway, NJ, IEEE International Conference on Robotics and Automation (ICRA 2020), May 2020, arXiv:1904.10097 (inproceedings)
Vinogradska, J., Bischoff, B., Achterhold, J., Koller, T., Peters, J.
Numerical Quadrature for Probabilistic Policy Search
IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(1):164-175, 2020 (article)
Kandukuri, R., Achterhold, J., Moeller, M., Stueckler, J.
Learning to Identify Physical Parameters from Video Using Differentiable Physics
Proc. of the 42th German Conference on Pattern Recognition (GCPR), 2020, GCPR 2020 Honorable Mention, preprint https://arxiv.org/abs/2009.08292 (conference)
Usenko, V., Stumberg, L. V., Stückler, J., Cremers, D.
TUM Flyers: Vision-Based MAV Navigation for Systematic Inspection of Structures
In Bringing Innovative Robotic Technologies from Research Labs to Industrial End-users: The Experience of the European Robotics Challenges, 136, pages: 189-209, Springer Tracts in Advanced Robotics, Springer International Publishing, 2020 (inbook)
Bosch, N., Achterhold, J., Leal-Taixe, L., Stückler, J.
Planning from Images with Deep Latent Gaussian Process Dynamics
Proceedings of the 2nd Conference on Learning for Dynamics and Control (L4DC), 120, pages: 640-650, Proceedings of Machine Learning Research (PMLR), (Editors: Alexandre M. Bayen and Ali Jadbabaie and George Pappas and Pablo A. Parrilo and Benjamin Recht and Claire Tomlin and Melanie Zeilinger), 2020, preprint arXiv:2005.03770 (conference)
Pinneri, C., Sawant, S., Blaes, S., Achterhold, J., Stueckler, J., Rolinek, M., Martius, G.
Sample-efficient Cross-Entropy Method for Real-time Planning
In Conference on Robot Learning 2020, 2020 (inproceedings)
Usenko, V., Demmel, N., Schubert, D., Stückler, J., Cremers, D.
Visual-Inertial Mapping with Non-Linear Factor Recovery
IEEE Robotics and Automation Letters (RA-L), 5(2):422-429, 2020, presented at IEEE International Conference on Robotics and Automation (ICRA) 2020, preprint arXiv:1904.06504 (article)
Mallick, A., Stückler, J., Lensch, H.
Learning to Adapt Multi-View Stereo by Self-Supervision
In Proceedings of the British Machine Vision Conference (BMVC), 2020, preprint https://arxiv.org/abs/2009.13278 (inproceedings)
2019
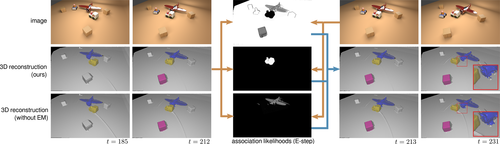
Strecke, M., Stückler, J.
EM-Fusion: Dynamic Object-Level SLAM With Probabilistic Data Association
In Proceedings IEEE/CVF International Conference on Computer Vision 2019 (ICCV), pages: 5864-5873, IEEE, 2019 IEEE/CVF International Conference on Computer Vision (ICCV), October 2019 (inproceedings)
Zhu, D., Munderloh, M., Rosenhahn, B., Stückler, J.
Learning to Disentangle Latent Physical Factors for Video Prediction
In Pattern Recognition - Proceedings German Conference on Pattern Recognition (GCPR), Springer International, German Conference on Pattern Recognition (GCPR), September 2019 (inproceedings)
2018
Ma, L., Stueckler, J., Wu, T., Cremers, D.
Detailed Dense Inference with Convolutional Neural Networks via Discrete Wavelet Transform
arxiv, 2018, arXiv:1808.01834 (techreport)